2019年8月9日、リクルートホールディングスは4月―6月期の連結純利益が前年同期比25%増で過去最高だったと発表しました。「じゃらん」(旅行)、「ホットペッパービューティ」(美容)、「リクナビNEXT」(中途採用)、「リクナビ」(新卒採用)など、データを活用したサービス事業が利益を生み出していたのです。
近年、リクルートが成長戦略として推進してきたのが、AIを使い、個人と企業とのマッチングを行う事業でした。今期はそれらが軒並み、業績を上げていたのですが、その中の一つ、「リクナビ」が手掛けていたサービスで問題が発覚しました。
■リクナビ、内定辞退率を企業に提供
2019年8月2日、就職情報サイト「リクナビ」を運営するリクルートキャリアが、本人からの同意を得ないまま、個人情報を使って「内定辞退率」を算出し、38社に有償で提供していたことが報じられました。
それを聞いた瞬間、私は思わず、耳を疑ってしまいました。リクナビといえば、大手の就職サイトです。それがユーザーである学生の信頼を踏みにじり、騙し討ちにするような行為で、大幅な利益を得ていたというのです。開いた口がふさがらず、私は不快感をおぼえ、不信感をつのらせてしまいました。
この時の報道によると、リクルートキャリアは、学生の閲覧履歴をAIで分析し、選考や内定を辞退する確率を5段階で評価するサービスを開発していたといいます。「リクナビDMPフォロー」と名付けられたこのサービスがどのような仕組みになっているのか、私にはよくわかりません。
ただ、ログインすれば、登録情報から自動的に個人が割り出されますし、その個人情報を閲覧履歴に紐づけて分析すれば、内定辞退の確率を個別に算出することができるのではないかという程度のことは推察できます。
このサービスは2018年3月から開始され、38社が利用していまたといいます。利用料金は関連サービスと合わせて年額400万円から500万円だったそうです。内定辞退率は企業にとってそれほど高い価値を持つ情報なのでしょう。
リクルートは人事担当者のニーズをしっかりと把握した上で、個別企業のニーズに合わせ、当該学生の内定辞退率を提供していました。学生の氏名を特定した上で、内定辞退率を算出し、企業ごとに情報を提供していたのです。
■内定辞退率の商品化
内定辞退率が、人事担当者からのニーズが高く、価値の高い情報であることは確かでした。学生と企業とのマッチングが適切でなければ、内定者が辞退してしまうということは今後も多々、起こるでしょう。
事前に当該学生の内定辞退率を把握することができれば、より承諾する可能性の高い学生に内定を出すことができると、企業が考えたとしても不思議はありません。企業にとって喉から手の出るほど欲しい情報なのです。ですから、内定辞退率の商品化は半ば当然のことだったといえるでしょう。
リクナビといえば、年間80万人もの学生が利用するサイトです。
こちら →https://job.rikunabi.com/2021/
ほとんどの学生はこのサイトで企業情報を得、就職活動を展開しています。その結果、リクナビには学生の個人情報や企業の閲覧履歴が膨大なデータとして蓄積されていました。ユーザー数が多ければ多いほど精度の高い情報が得られますし、サービスを改善していくこともできます。
ビッグデータの時代にはデータが価値を生みます。ビッグデータを処理する技術があり、インフラがあれば、内定辞退率を個別に算出し、商品化することは可能でした。最大手の就活サイト「リクナビ」だからこそできた情報サービスだといえます。
一方、「リクナビ」は、企業側のニーズを的確に把握しやすい立場にありました。だからこそ、企業が把握している特定の個人情報に紐づけ、閲覧履歴をAIで分析し、企業が知りたい学生の内定辞退率を算出することができたのです。この仕組みを図式化すれば、以下のようになります。
こちら →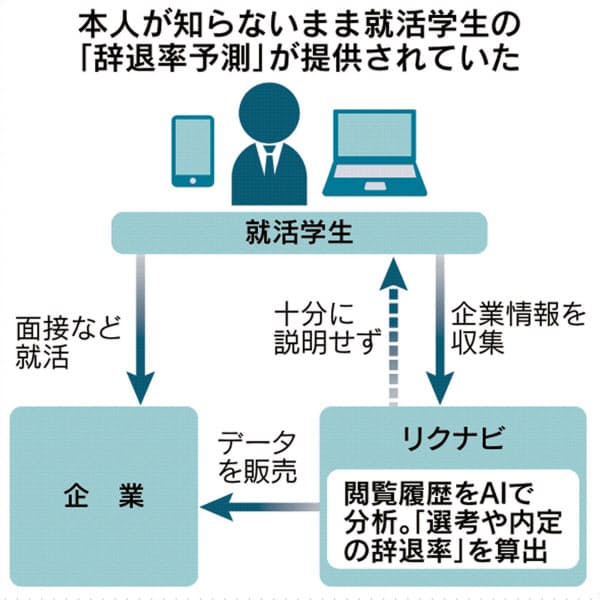
(2019年8月2日、日経新聞より。図をクリックすると、拡大します)
そもそも学生の閲覧履歴など、これまでは単なるデータに過ぎませんでした。ところが、AIの登場によって、ただのデータを価値ある情報に転換することができるようになりました。データを利活用し、ビジネスに結び付けることができるのが、閲覧履歴などの個人情報です。
もっとも、個人情報の利活用はビジネスに直結させることができる一方、個人の権利や利益を侵害する恐れがあります。
■本人の同意を得ず、個人情報を利用
今回、問題になっているのは、本人の同意を得ないまま、個人情報が使われていたことでした。先ほどの図を見てもわかるように、情報のやり取りはすべてネット上で行われています。
リクナビは学生と企業をつなぐプラットフォームですから、メインの顧客は学生だと思っていましたが、今回の一件からは、企業を重視したサービスが展開されていたことがわかります。企業のニーズに応えるために、本人の同意を得ないまま個人情報を使用していたのです。
明らかに、個人情報保護法に違反していますが、8月2日の時点では、リクルートキャリアはこのサービスをいったん、休止するとしか表明していませんでした。個人情報の扱いに関する認識が甘かったのかもしれません。
ところが、8月6日の報道では、このサービスを「休止する」から、「廃止する」に変更されていました。事件発覚後、リクナビに対する内部調査によって、個人情報保護法違反が明らかになったからでした。
例えば、「2019年3月にプライバシーポリシーを変更した際、一部の画面で反映できておらず、不適切に個人情報を取得した」ことが明らかになったといいます。システム上、本人の同意を得られない状況があったことが示されており、これによって、7983人の学生に影響が及んだと説明されています。
これはほんの一例です。これ以外の方法で、多くの個人情報が本人の同意なく、利用されていたのでしょう。正確に何人の学生の予測データが企業に販売されていたのか、この時点ではまだわかっていません。問題の根幹にかかわる情報の多くが不明だったのです。今後、このサービスの仕組みが明らかになってくれば、リクナビだけではなく、企業側の責任も問われる可能性がありました。
案の定、調査が進むと、企業は自社が持つ学生の個人データをリクナビに提供していたことが明らかになってきました。考えてみれば、確かに、企業からのデータ提供がなければ、特定の学生のその企業に対する「内定辞退率」を予測することなどできるはずがありません。
内部資料によると、企業はこのサービスを利用するために、リクルートから以下の作業を行うことが求められていました。すなわち、①採用のデータベースから、個人IDや選考結果、学歴など応募者情報をリクルート側に送付すること、②応募者に対して個人ID付きのURLの入ったメールを送信すること、等々です。
つまり、学生の内定辞退率を算出するには、リクルート側が持っているデータだけでは不可能で、当該企業からのデータが不可欠でした。双方のデータを収集してAIが分析した結果、学生がその企業の内定を辞退する確率を予測することができる仕組みだったのです。
■新卒者の内定辞退率の推移
企業が個人情報保護法に抵触してでも入手したかったのは、学生の内定辞退率でした。実際、手間暇かけて選考し、熟考の末、内定を出しても、辞退されてしまったのでは、元も子もありません。できることなら、確実に入社してくれる学生に内定を出したいというのが、企業の本音でしょう。
ところが、近年、内定を辞退する確率が高止まりしているようなのです。ネットで検索すると、新卒者の内定辞退率の推移を示すグラフを見つけることができました。2013年以降、内定辞退率は以下のように推移しています。
こちら →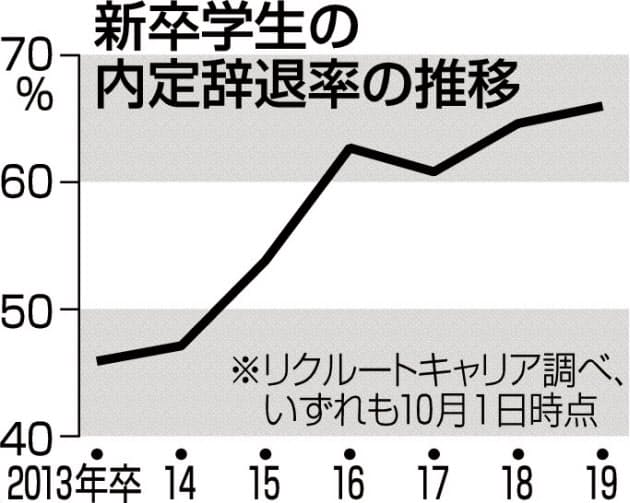
(日経新聞2018年12月1日付。図をクリックすると、拡大します)
上のグラフを見ると、2014年以降、内定辞退率は急速に上昇しています。2016年から2017年にかけては一旦、下がるのですが、その後、再び上昇しています。2019年春の卒業生の場合、内定辞退率は66%にも及び、過去最高を記録していました。ちなみに、学生が内定を得た企業数は平均2.45社だったそうです。
内定辞退率の推移をみていくと、企業の人事担当者がどれほど虚しい思いをし、徒労感を募らせていたかがわかろうというものです。しかも、内定辞退者数は60%以上で高止まりしています。このような状況が固定してくれば、企業の人事担当者が、内定を出した学生の辞退する確率を事前に把握したいと思うのも当然なのかもしれません。
ある企業の人事担当者によれば、1名の内定承諾者のために、2名に内定を出し、2名の内定者を出すために3名を社長面接に繋ぎ、3名の社長面接に繋ぐために5名を役員面接に繋ぐといいます。そして、5名の役員面接に繋ぐために10名のマネージャー面接を設定し、10名のマネージャー面接を設定するために20名の人事面接が必要だといいます。
さらに、20名の人事面接に繋ぐためにはイベントで300名の学生に接触しなければならないというのです。一人の内定承諾者を出すために、企業側はなんと300名の学生に接触していたのです。
採用のための一連のプロセスを見ると、企業が新卒採用にどれほど時間とコスト、心的エネルギーをかけているかがわかります。企業側の現状がわかってくると、次第に、この種の情報サービスは必要なのかもしれないと思うようになってきました。
とはいえ、本人の承諾を得て、個人情報を利用し、内定を得た学生の不利にならないようなシステムを構築することは可能なのでしょうか。個人情報を利用しなければ価値ある情報は得られず、本人の同意を求めれば、個人情報は得られない可能性があります。こうしてみると、現在の新卒一括採用システムそのものを考え直すことが必要になっているのかもしれません。
せっかく内定を得ても、学生はちょっとしたきっかけで容易に辞退してしまうというのが実態だとすれば、インターン制を充実させ、就職前に就労経験を積む必要があるでしょう。学生側の就労意識に問題があるのだとすれば、大学側でキャリア教育を充実させる必要があるかもしれません。
いずれにしても、これだけ内定辞退率が高いのは、新卒一括採用方式がもはや時代に合わなくなっているからだということも考えられるでしょう。
■新卒の通年採用の枠を拡大
そういえば、2019年4月22日、経団連は、新卒学生の通年採用を拡大することで大学側と合意し、正式に発表しました。これまでの春季一括採用に加え、通年採用の枠を拡大すると経団連が宣言したのです。
通年採用であれば、海外に留学した学生を採用しやすくなりますし、時期にとらわれずに優秀な学生を採用することができます。採用方式を多様化することによって、企業側は多様な人材を獲得することができるという判断から、経団連は新卒の採用方式を変更したのです。
大学側にしてみれば、通年採用を拡大することによって、新卒一括採用に合わせたカリキュラムではなく、大学で学ぶべき教育課程を充実させることができます。インターン制度を使い、専門知識を活かして仕事をする機会を学生に提供することもできます。このような可能性を考えると、通年採用は、企業にとっても大学にとっても通年採用方式にはメリットがあるといえるでしょう。
こちら →
(日経新聞2019年4月22日付より。図をクリックすると、拡大します)
もっとも、多様な採用方式が広がっていけば、新卒の採用時期が前倒しされる懸念があります。これについて経団連と大学側は、就職活動に多くの時間を割いて、大学4年時を浪費しないよう、「卒業要件を厳しくするよう徹底すべき」だという見解を確認し合ったと報道されています。学生にはしっかりと学んでもらい、知識、技能、見識などを習得してもらうという点で、受け入れる側と送り出す側は一致していたのです。
デジタル競争の時代、世界に通用する人材を採用しなければ、企業を持続的に発展させることはできません。文系・理系を問わず、基本的な数学やデータ分析力を養い、語学やリベラルアーツの習得が必要だということが共通認識になっているといえます。今春、経団連が打ち出した通年採用は時代の要請でもあったのです。
さて、日経新聞は2019年4月22日、通年採用の導入について、企業にアンケート調査を実施しました。その結果、すでに通年採用を始めていると答えた企業が24.5%、検討中が54.9%、検討していない企業は20.6%という結果でした。なんと8割弱の企業がすでに通年採用を実施しているか、検討していることがわかりました。
そして、通年採用を評価すると回答した企業は53.8%、評価しないはわずか10.4%でした。「評価する」理由の上位は、①「就活ルール」が形骸化、②留学生や外国人材を採用しやすくなる、③優秀な人材を確保しやすくなる、④学生との「ミスマッチ」が起きにくい、⑤学生が学業に注力できる、等々でした。
このアンケート調査の結果からは、企業が国内外を問わず、優秀な人材を求めていること、学生にはしっかりと勉強してほしいと望んでいること、等々が裏付けられました。組織内の和を重視するメンバーシップ型雇用から、能力重視のジョブ型雇用へと、明らかに変化し始めているのです。技術変化の激しいデジタルトランスフォーメーションの時代、優秀な人材の採用こそが、企業の命運を握るようになってきたからでしょう。
■ジョブ型雇用が意味するものは?
IT関連企業は当初から、ジョブ型雇用を実施していました。今回、注目されているのは、大企業が加盟している経団連が、このような雇用方針の転換を表明したことでした。これまで組織内調和を重視し、メンバーシップ型雇用を行ってきた経団連が、組織の調和を乱しかねないジョブ型雇用を打ち出したのです。
いったい、何故なのでしょうか。
人材サービス企業の大手エン・ジャパンの沼山祥史執行役員が、興味深い見解を披露しています。
ご紹介することにしましょう。
(https://style.nikkei.com/article/DGXMZO44519100Y9A500C1000000/?page=2より)
沼山氏は採用の現状について、「メンバーシップ型の採用をしている企業の給与制度は、年功序列を前提とした職能給であるため、ほしい専門人材に柔軟な条件提示ができない。結果、条件面で有利な外資やベンチャーに負けてしまう。こうした現状を何とかしないと企業として生き残れないという危機感がある」と述べています。ジョブ型採用に移行すれば、人材獲得競争の面でメリットが大きいと指摘するのです。
沼山氏さらに、「ジョブ型採用が広がると、学生時代から専門性を磨いたり職業経験を積んだりした人が就職の際に一段と有利になるだろう。だから、大学では専門的な勉強をしっかりとすることが求められる。また、インターンをするのも一つの手だ」といい、「就職してからも自己投資を怠らず、専門性に磨きをかけることが必要になってくる。年功序列のメンバーシップ型とは違い、ジョブ型は基本的に、自分で努力しないとキャリアアップも昇給もままならない」と述べています。
最近、『AERA』の2019年8月5日号を読んだところ、「新卒の年収も一千万円時代」というタイトルの記事が掲載されていました。これもまた、ジョブ型採用の一例といえるでしょう。
■新卒年収、1000万円時代?
ネット関連企業のDeNAは2017年、高いAI知識を持つ学生のための採用枠「エンジニア職AIスペシャルコース」を設け、年収を「600万円以上、最高1千万円」としたそうです。
タイトルを見たとき、あまりにも高額の年収に驚いてしまったのですが、これは、優秀な学生をつなぎとめるためのジョブ型採用の一つでした。
DeNAのAIシステム部長は、実際に1千万円の年収を提示する学生には最低条件として、「研究者としてトップレベルであること」、「学生時代に国際学会で発表し、論文が採択されていること」、「事業やサービスの提供を先導できること」などを求めるといいます。
破格の年収には驚いてしまいましたが、採用基準をみると、極めて高い知識や技能、経験が求められています。グローバル化し、デジタル化した社会状況の中で、十分に能力を発揮できる人材が必要とされているのでしょう。
人材獲得競争がし烈になっている今、求める人材を獲得しようとすれば、考えられないほど多額の報酬を提示せざるをえないようになっているようです。
さて、2017年に「エンジニア職AIスペシャルコース」で、DeNAに採用された学生は、AI専門職の採用枠を設けている企業をターゲットに就職活動をしていたといいます。結果として、大学、大学院でしっかりと研究してきたことが評価されて、採用されました。
大学や大学院でしっかりと学び、成果を出していれば、専門職を遂行できる人材だとして評価され、企業から高い報酬で採用されるのです。入社してから、専門を活かしてモチベーション高く働くことができれば、職場でも成果を上げやすく、企業も満足するというwin-winの関係が生み出されます。新卒学生に高い報酬を支払っても、高い確率で、それに見合う成果が得られるのです。
DeNAと同様、新卒にも高額の報酬で報いるという企業は他にもありました。
こちら →
(『AERA』の2019年8月5日号より。図をクリックすると、拡大します)
これを見ると、主に研究者、AIエンジニアとして力量のある人材が求められていることがわかります。デジタル技術に長けた優秀な人材を採用しなれば、企業の存続が危ぶまれる時代になっているからでしょう。
■ビッグデータの時代、何が求められているのか
デジタル競争の時代を迎え、ビッグデータ、AIが主要な役割を果たすようになっています。企業が求める人材もそれに応じて変化しており、高度なデジタル人材の獲得競争がし烈になっているようです。
ところが、従来の給与体系では優秀な若い人材の雇用は難しく、企業の成長を維持することはできなくなっています。既存社員よりも多額の報酬を支払ってでも、有能な新卒を採用しなければ、デジタルトランスフォーメーションへの対応が不可能になっているのです。
そのような状況下で発覚したのが、就活サイト「リクナビ」の個人情報保護違反の案件でした。内部調査が進むにつれ、企業もまた学生の個人情報を本人の同意なく、リクルートに提供していたことが明らかになりました。就活サイトと企業が共同して学生の個人情報を勝手に利用し、個別に内定辞退率を算出し、新たな情報サービスとして企業に有償で提供していたのです。
ビッグデータが価値を持つ時代を反映するような案件でした。
一方、新卒に1000万円の報酬を提示する企業が出てきました。採用基準をみると、グローバルに展開するデータ経済の時代に活躍できる能力や技能、経験を備えていることが条件になっています。
今回、ご紹介した新卒採用を巡る一連の案件はいずれも、デジタルフォーメーション時代に向けて社会が変革している過程で生み出されたものだといえるでしょう。新たな事業を創出し、企業が持続的に発展していくには、技術力、知識、経験、人間性など、きわめて高い能力を備えた人材が不可欠になっていることがわかります。
さらに、「リクナビ」の一件では、個人情報が大量に集積すれば、新たな価値を生み出すこともわかりました。改めて、どのようにすれば個人情報を守れるのか、個人の権利や利益を侵害しないで利用するには個人情報をどのように扱うべきなのか、ルールの徹底が必要だと思いました。(2019/8/16 香取淳子)